
围绕 transformers 构建现代 NLP 开发环境

来源:阿里开发者
阿里妹导读
本文将从“样本处理”,“模型开发”,“实验管理”,“工具链及可视化“ 几个角度介绍基于 tranformers 库做的重新设计,并简单聊聊个人对“软件2.0”的看法。Intro
最近在 review 和重构团队的 NLP 炼丹基础设施,并基于 tranformers 库做了重新设计,本文将从“样本处理”,“模型开发”,“实验管理”,“工具链及可视化“ 几个角度介绍这项工作,并简单聊聊个人对“软件2.0”的看法。样本处理
核心思路:函数式,流式,组合式,batch 做多路融合,对 datasets 兼容虽然随机读取的数据集用起来最方便,但是在大部分实际应用场景中,随机读取往往难以实现。不过,我们能构造流式读取的接口,例如:MaxCompute(ODPS) :无法通过行号快速读取数据,但是有 Tunnel 接口支持从某个下标开始顺序读取数据。
文件系统:包括本地文件,HDFS,以及OSS等对象存储。本地文件虽然能用 lseek() 等函数快速跳转到某个位置(且该操作通常为 O(1)),但是如果每条样本字节数不一样,封装为随机读取还是非常复杂,但是做成流式读取就很容易。其他云上的存储介质更是如此。
消息队列:例如 MetaQ,天然流式的数据,可以主动拉取,也可以以订阅的方式封装流式读取的接口。
在我们设计的数据加载框架中,可以用以下代码来实现 ”分别从两个 ODPS 表里读取正样本和负样本,用 func 函数处理后,在 batch 内以 1:1 的方式混合,正负样本分别用两个线程并行读取“。positive = Threaded(Map(func, ODPS(access_id, access_key, project, positive_sample_table_name, read_once=False)))negative = Threaded(Map(func, ODPS(access_id, access_key, project, negative_sample_table_name, read_once=False)))combined = Combine([positive, negative], sample_weight=[1.0, 1.0])返回的 combined 变量是一个普通的 python generator,可以直接从中获取数据,也可以将其传入 huggingface 的 datasets 模块。该方案优势很明显:灵活可扩展,懒加载节约资源。# 直接读取数据for data in combined: print(data)# 使用 huggingface datasets 模块# 之后可以直接用在 transformers.Trainer 类中参与训练import datasetstrain_dataset = datasets.IterableDataset.from_generator(combined, gen_kwargs={"ranks": [0,1,2,3], "world_size": 4} # 支持分布式训练)技术问题:对分布式训练的支持
datasets.IterableDataset.from_generator 函数,可以额外传入一个名为 gen_kwargs 的 dict 类型参数,若某个 value 类型是 list,则会在 dataloader num_workers 数大于 1 的时候,自动进行分片,将分片后的 list 传给底层的 generator[1]。huggingface 在开发模块时,经常使用这种“隐含的调用规约”,在用户输入和输出满足某些条件时,触发特定的功能,这一点在他们开发的其他模块中也有所展现。在我们的设计中,所有加载数据的 generator 都默认接受 ranks 和 world_size 两个额外参数,其中 ranks 为 list 类型,代表该 generator 处理的分片列表,world_size 时分片的总数,在实现加载逻辑时,根据这两个参数,读取对应分片的数据。def _ODPS(access_id, access_key, project, table_name, partition_spec, read_once, retry, endpoint, ranks=None, world_size=None): # 加载 ranks + world_size 对应分片数据,实现略(计算读取 range 后,使用 PyODPS 加载数据)def ODPS(access_id, access_key, project, table_name, partition_spec=None, read_once=True, retry=True, endpoint="http://xxxxxx"): return partial(_ODPS, access_id, access_key, project, table_name, partition_spec, read_once, retry, endpoint)注意,这里使用了partial返回了一个原始函数“科里化”后的版本,这是使 generator 可组合的关键设计。
模型开发
核心思路:继承 PreTrainedModel,PreTrainedCofig,PreTrainedTokenizer 基类,与 transformers 体系打通。通过 mixin / monkey patching 方式,扩充现有框架功能,例如对 OSS 模型加载/存储的支持。通过继承 PreTrainedModel,PreTrainedCofig,PreTrainedTokenizer 三件套,模型就能使用 transformers 框架的一系列基础设施,从而实现如下效果:# 加载我们项目组开发的分类模型(多任务层次分类)model = BertForMultiTaskHierarchicalClassification.from_pretrained("./local_dir")# or 从 OSS 直接加载model = BertForMultiTaskHierarchicalClassification.from_pretrained("oss://model_remote_dir")# 保存模型model.save_pretrained("./local_dir")model.save_pretrained("oss://model_remote_dir")# 加载我们使用 C++ 开发的 tokenizertokenizer = ShieldTokenizer.from_pretrained("oss://model_remote_dir")# 使用 AutoClass 实现相同功能,不需要指定特定的模型类名,由框架自动推断model = AutoModel.from_pretrained("oss://model_remote_dir")tokenizer = AutoTokenizer.from_pretrained("oss://model_remote_dir")# 扩展 transformers 默认的 pipeline# 增加 multitask-hierarchical-classification 任务pipe = pipeline("multitask-hierarchical-classification", model=model, tokenizer=tokenizer)print(pipe("测试文本"))可以看出,我们自研的模型使用方式和 transformers 上的开源模型别无二致,甚至还能直接从 OSS 上加载模型,极大降低了模型的使用学习成本。
如何支持集团内的存储介质
为了使 transformers 框架中的对象支持 OSS 存储,我们使用了 mixin 的方式进行了逻辑改写,让所有自研的新模型都继承 OSSRemoteModelMixin,对于 AutoModel,则直接覆盖他们的 from_pretrained 方法。class OSSRemoteModelMixin(object): """ 支持用户在 from_pretrained 和 save_pretrained 时按照 oss://path 的格式指定路径 (bucket, ak, sk 需要在环境变量中指定, 见 util.oss_util 类) 可以用于所有包含 from_pretrained 和 save_pretrained 方法的类 (config or tokenizer or model) """ @classmethod def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], *model_args, **kwargs): pretrained_model_name_or_path = convert_oss_to_local_path(cls, pretrained_model_name_or_path, kwargs.get(cache_dir, risk_shield.CACHE_DIR)) return super(OSSRemoteModelMixin, cls).from_pretrained( pretrained_model_name_or_path, *model_args, **kwargs) def save_pretrained( self, save_directory: Union[str, os.PathLike], *args, **kwargs ): prefix = "oss://" oss_path = save_directory if save_directory.startswith(prefix): # save to a temp dir # ....... # 将文件拷贝到 OSS,实现略 return res else: res = super(OSSRemoteModelMixin, self).save_pretrained(save_directory, *args, **kwargs)# 让模型继承自 OSSRemoteModelMixin 就会自动获得 OSS 存取的能力class BertForMultiTaskHierarchicalClassification( OSSRemoteModelMixin, BertPreTrainedModel): config_class = BertForMultiTaskHierarchicalClassificationConfig def __init__(self, config:BertForMultiTaskHierarchicalClassificationConfig): # .....# 对于 AutoModel,则直接覆盖他们的 from_pretrained 方法。def patch_auto_class(cls): """ 让 AutoClass 支持 OSS 路径 """ old_from_pretrained = cls.from_pretrained def new_from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], *model_args, **kwargs): pretrained_model_name_or_path = \ convert_oss_to_local_path(cls, pretrained_model_name_or_path, kwargs.get(cache_dir, risk_shield.CACHE_DIR)) return old_from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs) cls.from_pretrained = classmethod(new_from_pretrained)同样,让框架支持 HDFS,ODPS Volumn 等其他存储介质,也可采用相同的方案。
如何使用自己的 Tokenizer
并不是所有业务都适合直接使用 BertTokenizer,例如,对于我们所在的业务,采用一种融合了外部知识信息的特殊方式进行 tokenize,用来提升模型效果。而且,我们的预测服务是 C++ 代码,为了保证预测和训练时的 tokenize 逻辑完全一致,我们基于 ctypes,用同一套 C++ 代码实现 python tokenize 的底层逻辑,并在上层做好 PreTrainedTokenizer 的接口兼容。为了实现一个兼容 PreTrainedTokenizer 的 C++ tokenizer,我们重新实现了以下接口,有类似需求的同学可以参考。类变量 vocab_files_names__getstate__, __setstate__,解决 C++ 对象的 pickle 问题_convert_token_to_id_convert_id_to_tokenconvert_ids_to_tokens__setattr__vocab_sizeget_vocabtokenizesave_vocabulary_pad 对 tokenize 后的结果进行 pad,主要用在 trainer 里的 collator_encode_plus 处理单条文本_batch_encode_plus 处理 batch 文本使用我们自研的 tokenizer,在单核下比 huggingface 使用 Rust 开发的 BertTokenizerFast 在多核下更快。
训练代码
符合 transformers 标准的模型,可以直接使用框架的 Trainer 完成模型训练,并通过 data_collator,callback 机制,对训练过程进行定制。下面结合上面介绍的内容,给出训练一个完整分类模型的代码(忽略不重要的细节)。def compute_metrics(model, eval_pred): logits, labels = eval_pred # 针对层次分类设计的评估指标 metrics = evaluate_multitask_hierarchical_classifier(model, labels) return metrics# 定义模型tokenizer = ShieldTokenizer.from_pretrained("oss://backbone")config = BertForMultiTaskHierarchicalClassificationConfig.from_pretrained("oss://backbone")config.multi_task_config = { # 这里的分类树仅是例子 "main": { "hierarchical_tree": ["父类别1", "父类别2", ["父类别3", ["父类别3-子类别1", "父类别3-子类别2", "父类别3-子类别3", "父类别3-子类别4"] ] ] }}model = BertForMultiTaskHierarchicalClassification.from_pretrained("./backbone")# 定义训练数据加载策略positive = Threaded(Map(func, ODPS(access_id, access_key, project, positive_sample_table_name, read_once=False)))negative = Threaded(Map(func, ODPS(access_id, access_key, project, negative_sample_table_name, read_once=False)))combined = Combine([positive, negative], sample_weight=[1.0, 1.0])train_ds = datasets.IterableDataset.from_generator(combined)training_arg = TrainingArguments( output_dir="./output", overwrite_output_dir=True, num_train_epochs=4, # ... # 其他训练参数 # ... dataloader_num_workers=2,)trainer = Trainer( model=model, args=training_arg, train_dataset=train_ds, tokenizer=tokenizer, eval_dataset=val_ds, compute_metrics=partial(compute_metrics, model), # 针对层次分类开发的 collator data_collator=MultiTaskHierarchicalClassifierCollator( tokenizer=tokenizer, model=model, max_length=max_length, task_label_smooth=task_label_smooth ))# 将实验指标写入 tensorboard 并上传到 OSStrainer.add_callback(OSSTensorboardWriterCallback("experiment/v1/"))trainer.train()从代码中可以看出,唯一需要改动的,就是 data_collator(多进程组 batch 及样本后处理) 和 compute_metrics 逻辑,根据不同的任务头,需要开发特定的 collator,其他都是标准的模版代码。使用 Trainer 类后,可以使用 transformers 框架的强大功能,例如对 DDP,deepspeed 等训练技术的支持,以及对梯度爆炸等问题的 debug 能力。(设置 debug="underflow_overflow")需要注意的是,为了让 Trainer 正常工作,你的模型的返回必须符合以下格式,如果不喜欢这种 “隐含的调用规约”,可以做一个 trainer 的子类对逻辑进行更彻底的重写。第一个元素是 loss,trainer 自动优化该值。
后续的元素只能是 python dict / list / tuple / tensor,tensor 第一维的大小必须和 batch size 一致。最理想的情况就是一个二维 logits 矩阵。模型部署
针对项目中用到的几种部署形态,重新封装部署,预测代码。import risk_shieldfrom transformers import AutoTokenizer, AutoModelmodel = AutoModel.from_pretrained("oss://model.tar.gz")tokenizer = AutoTokenizer.from_pretrained("oss://model.tar.gz")# 导出 ONNXmodel.export_onnx(output_dir)# 或导出 TensorRTmodel.export_tensorrt(output_dir)# 或导出 Tensorflow(ODPS 部署)model.export_tf_saved_model(output_dir)# 导出切词器到同一目录tokenizer.save_pretrained(output_dir)########################## 部署时加载对应 pipelinefrom risk_shield import ONNXHierarchicalClassifierPipelinefrom risk_shield import TensorRTHierarchicalClassifierPipelinefrom risk_shield import TFSavedModelHierarchicalClassifierPipelinepipe = TensorRTHierarchicalClassifierPipeline(output_dir)result= pipe("测试文本")最小化依赖在设计时,我希望整个框架对开发环境的依赖尽可能低,因此只需要 transformers 就能运行,这套“工具集” 本质上是 transformers 的外挂补丁,遵循该库的所有接口协议,因此,自然是“高内聚”,“低耦合”的,可以选择使用其中的部分,例如只用分类头,但是自己写 trainer,或者只用模型,不用数据加载模块。可以在 GPU 服务器或者 Mac 笔记本上训练模型。实验管理
Trainer 类原生支持 wandb [2]等平台,对实验过程中的指标进行查看&对比&管理,由于这涉及到将实验数据上传到外网,我们选择将实验指标以 tensorboard 的格式保存在 OSS 中,上面代码的 OSSTensorboardWriterCallback("experiment/v1/") 部分就实现了这一功能。此外,我们在开发了一个实时查看 OSS 上 tensorboard 的命令行工具,一般我们都会在 GPU 服务器上训练模型和上报指标,在各自的笔记本上查看和分析指标,你看,不需要依赖 wandb 这种外部平台,也能实现类似的指标管理能力。
1. 命令行工具,实时拉取 OSS 上的 tensorboard

2. 超参搜索及指标对比
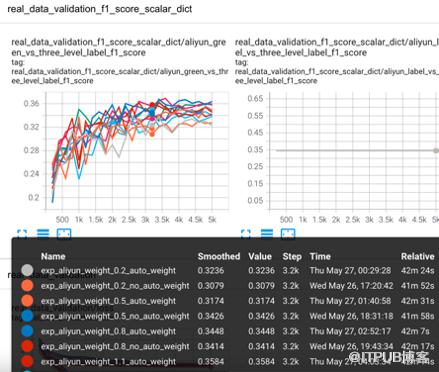
工具链及可视化
结合 gradio 库,我们对所有模型任务都开发了可视化工具,在模型训练中,可以随时进行效果试用,具体可以参考 gradio 文档,由于我们实现了对 AutoModel 的支持,因此无论模型采用什么 backbone,只要任务一致,就能使用同一个工具进行查看分析。1. 命令行工具,加载 OSS 上保存的模型 checkpoint 并打开浏览器页面

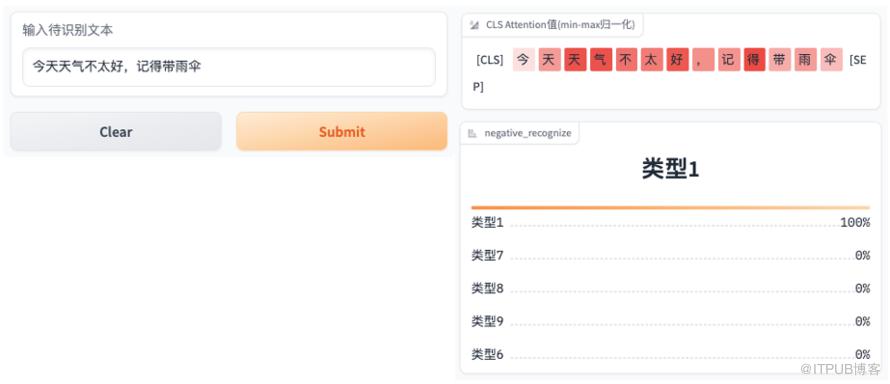
2. 基于 gradio 开发的 debug 工具(分类模型)
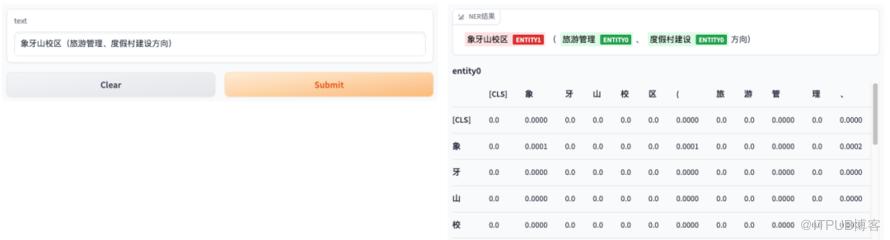
3. 基于 gradio 开发的 debug 工具(NER 模型)
“软件2.0”
Andrej Karpathy,前特斯拉人工智能负责人,在 2017 年发表了一篇名为《Software 2.0》 [3]的文章,文中预言了深度学习将逐步替代掉大部分传统“手工”算法,而深度学习技术将从某个传统算法系统的子模块,演化成为算法系统的主要构成部分(例如自动驾驶),或者如 Andrej 所说:“抱歉,梯度下降能比你写出更好的代码”。 他预言,为了实现软件2.0,需要一整套服务于深度模型开发的工具栈,就像传统软件需要 pip,conda 这类包管理器(package manager),GDB 这类 debug 工具,Github 这类开源社区一样,深度学习也需要模型 debug 工具,模型和数据集的管理器和开源社区。但他没有预言到的是,类transformer 架构在之后的年月里大放异彩,不仅统一了 NLP 领域,而且正在逐步统一 CV 等其他领域。“预训练-微调” 成为业界最常见的模型开发范式。而 huggingface 公司,借着 transformers 库的东风,以及围绕它建设的模型开源社区(huggingface hub)[4],成为当前 NLP 开发事实上的标准,连目前最火的大模型,都选择在 huggingface 发布,例如 ChatGLM:
他预言,为了实现软件2.0,需要一整套服务于深度模型开发的工具栈,就像传统软件需要 pip,conda 这类包管理器(package manager),GDB 这类 debug 工具,Github 这类开源社区一样,深度学习也需要模型 debug 工具,模型和数据集的管理器和开源社区。但他没有预言到的是,类transformer 架构在之后的年月里大放异彩,不仅统一了 NLP 领域,而且正在逐步统一 CV 等其他领域。“预训练-微调” 成为业界最常见的模型开发范式。而 huggingface 公司,借着 transformers 库的东风,以及围绕它建设的模型开源社区(huggingface hub)[4],成为当前 NLP 开发事实上的标准,连目前最火的大模型,都选择在 huggingface 发布,例如 ChatGLM: 这些已经有了软件 2.0 的雏形。因此,只有做到与 transformers 框架和接口标准的充分整合,才能真正与开源社区与行业的技术进步接轨,虽然我们无法使用外部的软件 2.0 工具栈(例如上面提到的 wandb),但是我们可以在团队内部以软件 2.0 的方式工作,例如把 OSS 作为一种 huggingface hub 的替代物(😂),在本地启动 gradio 作为 spaces [5]的替代物。使用 OSS 替代 hub 还有一个额外的好处:与中心化的 hub 不同,每个用户(项目组)可以使用自己私有的 OSS 地址,用 OSS 自带的 ACL 进行权限控制。我们在开发环境中,实现了 push/pull 的能力,对于项目协作/复用来说足够了。-- 团队 A 同学发布模型到 OSSshield_publish ~/checkpoint_dir https://xxxx.aliyuncs.com/../xxxx.tar.gzWARNING:root:从本地目录上传:~/checkpoint_dirxxxx.tar.gz: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [01:50<00:00, 1.11s/it]WARNING:root:已发布OSS(url):https://xxxx.aliyuncs.com/../xxxx.tar.gz-- 团队 B 同学使用 OSS 上“内部开源”的模型AutoModel.from_pretrained("https://xxxx.aliyuncs.com/../xxxx.tar.gz")当然,在国内也有大量与 huggingface 类似的平台,例如由达摩院开发的 modelscope 社区[6] 和百度的 paddlenlp[7]。随着软件 2.0 工具栈的成熟,算法开发流程将逐步标准化,工程化,流水线化,不仅大量非科班的玩家都能用 LoRA 微调大模型,用 diffusers 生成人物了,甚至连 AI 都能开发软件[8]了,那么在未来,“算法工程师” 这个 title 会变成什么呢,会调用 import transformers 算不算懂 NLP 呢?这道题作为 课后练习,留给同学们进行思考!参考链接:
这些已经有了软件 2.0 的雏形。因此,只有做到与 transformers 框架和接口标准的充分整合,才能真正与开源社区与行业的技术进步接轨,虽然我们无法使用外部的软件 2.0 工具栈(例如上面提到的 wandb),但是我们可以在团队内部以软件 2.0 的方式工作,例如把 OSS 作为一种 huggingface hub 的替代物(😂),在本地启动 gradio 作为 spaces [5]的替代物。使用 OSS 替代 hub 还有一个额外的好处:与中心化的 hub 不同,每个用户(项目组)可以使用自己私有的 OSS 地址,用 OSS 自带的 ACL 进行权限控制。我们在开发环境中,实现了 push/pull 的能力,对于项目协作/复用来说足够了。-- 团队 A 同学发布模型到 OSSshield_publish ~/checkpoint_dir https://xxxx.aliyuncs.com/../xxxx.tar.gzWARNING:root:从本地目录上传:~/checkpoint_dirxxxx.tar.gz: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [01:50<00:00, 1.11s/it]WARNING:root:已发布OSS(url):https://xxxx.aliyuncs.com/../xxxx.tar.gz-- 团队 B 同学使用 OSS 上“内部开源”的模型AutoModel.from_pretrained("https://xxxx.aliyuncs.com/../xxxx.tar.gz")当然,在国内也有大量与 huggingface 类似的平台,例如由达摩院开发的 modelscope 社区[6] 和百度的 paddlenlp[7]。随着软件 2.0 工具栈的成熟,算法开发流程将逐步标准化,工程化,流水线化,不仅大量非科班的玩家都能用 LoRA 微调大模型,用 diffusers 生成人物了,甚至连 AI 都能开发软件[8]了,那么在未来,“算法工程师” 这个 title 会变成什么呢,会调用 import transformers 算不算懂 NLP 呢?这道题作为 课后练习,留给同学们进行思考!参考链接:
[1]https://huggingface.co/docs/datasets/v2.13.1/en/package_reference/main_classes#datasets.Dataset.from_generator
[2]https://wandb.ai/site
[3]https://karpathy.medium.com/software-2-0-a64152b37c35
[4]https://huggingface.co/docs/hub/index
[5]https://huggingface.co/spaces
[6]https://modelscope.cn/models
[7]https://huggingface.co/docs/hub/paddlenlp
[8]https://arxiv.org/abs/2307.07924扫一扫,关注我们
