
使用Java客户端将数据加载到Grakn知识图中
本教程说明了如何使用 Grakn的Java Client 将CSV,JSON或XML格式的数据集迁移到Grakn知识图中 。
我们将在本文中讨论的 phone_calls. 知识图 称为 此知识图的模式在 此处 的前一篇文章中定义 。
如果您已经熟悉Grakn,并且您需要的只是一个迁移示例,您会发现 这个Github存储库 很有用。 如果,另一方面,你不熟悉的技术,一定要首先完成 定义模式 的 phone_calls 知识图,使用Java数据迁移到Grakn阅读进行了详细的指导。
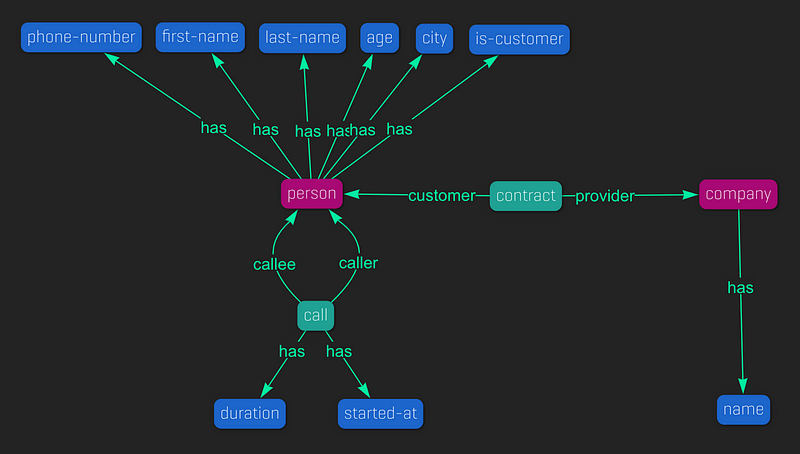
快速查看phone_calls架构
在我们开始迁移之前,让我们快速提醒一下 phone_calls 知识图 的架构是如何形成的 。
将数据迁移到Grakn
我们将概述迁移的发生方式。
首先,我们需要与我们的Grakn键空间进行对话。 为此,我们将使用 Grakn 的 Java客户端 。
我们将遍历每个数据文件,提取每个数据项并将其解析为JSON对象。
我们将每个数据项(以JSON对象的形式)传递给其对应的模板。 模板返回的是用于将该项插入Grakn的Graql查询。
我们将执行每个查询以将数据加载到目标键空间 - phone_calls 。
在继续之前,请确保已安装Java 1.8并在 计算机上 运行 Grakn服务器 。
入门
创建一个新的Maven项目
该项目使用SDK 1.8并命名 phone_calls 。 我将使用IntelliJ作为IDE。
将Grakn设置为依赖关系
修改 pom.xml 以包含最新版本的Grakn(1.4.2)作为依赖项。
<?xml version =“1.0”encoding =“UTF-8”?> < project xmlns = “http://maven.apache.org/POM/4.0.0” xmlns:xsi = “http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation = “http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd” > < modelVersion > 4.0.0 </ modelVersion > < groupId > ai.grakn.examples </ groupId > < artifactId > migrate-csv-to-grakn </ artifactId > < version > 1.0-SNAPSHOT </ version > < 存储库> < repository > < id >发布</ id > < url > https://oss.sonatype.org/content/repositories/releases </ url > </ repository > </ repositories > < properties > < grakn.version > 1.4.2 </ grakn.version > < maven.compiler.source > 1.7 </ maven.compiler.source > < maven.compiler.target > 1.7 </ maven.compiler.target > </ properties > < dependencies > < 依赖> < groupId > ai.grakn </ groupId > < artifactId > client-java </ artifactId > < version > $ {grakn.version} </ version > </ dependency > </ dependencies > </ project >配置日志记录
我们希望能够配置Grakn注销的内容。 为此,请修改 pom.xml 以排除 slf4j 附带 grakn 并 logback 作为依赖 项添加 。
<?xml version =“1.0”encoding =“UTF-8”?> < project xmlns = “http://maven.apache.org/POM/4.0.0” xmlns:xsi = “http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation = “http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd” > < modelVersion > 4.0.0 </ modelVersion > <! - ... - > < dependencies > < 依赖> < groupId > ai.grakn </ groupId > < artifactId > client-java </ artifactId > < version > $ {grakn.version} </ version > < exclusions > < 排除> < groupId > org.slf4j </ groupId > < artifactId > slf4j-simple </ artifactId > </ exclusion > </ exclusions > </ dependency > < 依赖> < groupId > ch.qos.logback </ groupId > < artifactId > logback-classic </ artifactId > < version > 1.2.3 </ version > </ dependency > </ dependencies > </ project >接下来,添加一个 logback.xml 使用以下内容 调用的新文件 并将其放在下面 src/main/resources 。
< configuration debug = “false” > < root level = “INFO” /> </ configuration >创建迁移类
在 src/main 创建一个名为的新文件 Migration.java 。 这是我们要编写所有代码的地方。
包括数据文件
选择以下数据格式之一并下载文件。 下载四个文件中的每个文件后,将它们放在 src/main/resources/data 目录下。 我们将使用它们将数据加载到我们的 phone_calls 知识图中。
随后的所有代码都将被写入 Migration.java 。
指定每个数据文件的详细信息
在此之前,我们需要一个结构来包含读取数据文件和构建Graql查询所需的详细信息。 这些细节包括:
数据文件的路径,和
接收JSON对象并生成Graql插入查询的模板函数。
为此,我们创建了一个名为的新子类 Input 。
导入 mjson。杰森 ; 公共 类 迁移 { abstract static class Input { 字符串 路径 ; public Input(String path){ 这个。path = path ; } String getDataPath(){ return path ;} abstract String template(Json 数据); } }在本文的后面,我们将看到如何 Input 创建类 的实例 ,但在我们开始之前,让我们将 mjson 依赖 项添加 到 文件中 的 dependencies 标记中 pom.xml 。
< 依赖> < groupId > org.sharegov </ groupId > < artifactId > mjson </ artifactId > < version > 1.4.0 </ version > </ dependency >是时候初始化了 inputs 。
下面的代码调用 initialiseInputs() 返回集合的方法 inputs 。 然后,我们将使用 input 此集合中的 每个 元素将每个数据文件加载到Grakn中。
//其他进口 导入 java。util。ArrayList ; 导入 java。util。收藏 ; 公共 类 迁移 { 抽象 静态 类 输入 {...} public static void main(String [] args){ 集合< Input > inputs = initialiseInputs(); } static Collection < Input > initialiseInputs(){ 集合< Input > inputs = new ArrayList <>(); // 接下来的是 回报 输入 ; } }公司的输入实例
//进口 公共 类 迁移 { 抽象 静态 类 输入 {...} public static void main(String [] args){...} static Collection < Input > initialiseInputs(){ 集合< Input > inputs = new ArrayList <>(); 输入。add(new Input(“data / companies”){ @覆盖 public String template(Json company){ 返回 “插入$ company isa company has name” + 公司。at(“name”)+ “;” ; } }); 回报 输入 ; } }input.getDataPath() 会回来的 data/companies 。
鉴于 company 是
{ name:“Telecom” }input.template(company) 将返回
插入 $公司 ISA 公司 拥有 的名称 “电信” ;一个人的输入实例
//进口 公共 类 迁移 { 抽象 静态 类 输入 {...} public static void main(String [] args){...} static Collection < Input > initialiseInputs(){ 集合< Input > inputs = new ArrayList <>(); 输入。add(new Input(“data / companies”){...}); 输入。add(new Input(“data / people”){ @覆盖 public String template(Json person){ //插入人 String graqlInsertQuery = “insert $ person isa person has phone-number” + person。at(“phone_number”); 如果(! 人。有(“FIRST_NAME” )){ //人不是客户 graqlInsertQuery + = “has is-customer false” ; } else { //人是顾客 graqlInsertQuery + = “has is-customer true” ; graqlInsertQuery + = “有名字” + 人。at(“first_name”); graqlInsertQuery + = “有姓氏” + 人。at(“last_name”); graqlInsertQuery + = “有城市” + 人。在(“城市”); graqlInsertQuery + = “有年龄” + 人。在(“年龄”)。asInteger(); } graqlInsertQuery + = “;” ; return graqlInsertQuery ; } }); 回报 输入 ; } }input.getDataPath() 会回来的 data/people 。
鉴于 person 是
{ phone_number:“+ 44 091 xxx” }input.template(person) 将返回
插入 $人 拥有 电话- 数字 “+44 091 XXX” ;并给予 person 被
{ 冷杉- 名称:“成龙”,最后- 名:“乔”,城市:“即墨”,年龄:77,PHONE_NUMBER:“+00 091 XXX” }input.template(person) 将返回
插入 $人 拥有 电话- 数字 “+44 091 XXX” 具有 第一- 名字 “成龙” 已经 过去- 名字 “乔” 有 城 “即墨” 具有 年龄 77 ;合同的输入实例
//进口 公共 类 迁移 { 抽象 静态 类 输入 {...} public static void main(String [] args){...} static Collection < Input > initialiseInputs(){ 集合< Input > inputs = new ArrayList <>(); 输入。add(new Input(“data / companies”){...}); 输入。add(new Input(“data / people”){...}); 输入。add(new Input(“data / contracts”){ @覆盖 public String template(Json contract){ //匹配公司 String graqlInsertQuery = “匹配$ company isa company has name” + contract。at(“company_name”)+ “;” ; //匹配人 graqlInsertQuery + = “$ customer isa person has phone-number” + contract。at(“person_id”)+ “;” ; //插入合同 graqlInsertQuery + = “insert(provider:$ company,customer:$ customer)isa contract;” ; return graqlInsertQuery ; } }); 回报 输入 ; } }input.getDataPath() 会回来的 data/contracts 。
鉴于 contract 是
{ company_name:“Telecom”,person_id:“ + 00 091 xxx” }input.template(contract) 将返回
比赛 $公司 ISA 公司 拥有 的名称 “电信” ; $客户 ISA 人 拥有 电话- 数字 “+00 091 XXX” ; insert(provider:$ company,customer:$ customer)isa contract ;呼叫的输入实例
//进口 公共 类 迁移 { 抽象 静态 类 输入 {...} public static void main(String [] args){...} static Collection < Input > initialiseInputs(){ 集合< Input > inputs = new ArrayList <>(); 输入。add(new Input(“data / companies”){...}); 输入。add(new Input(“data / people”){...}); 输入。add(new Input(“data / contracts”){...}); 输入。add(new Input(“data / calls”){ @覆盖 public String template(Json call){ //匹配来电者 String graqlInsertQuery = “match $ caller isa person has phone-number” + call。at(“caller_id”)+ “;” ; //匹配被叫者 graqlInsertQuery + = “$ callee isa person has phone-number” + call。at(“callee_id”)+ “;” ; //插入电话 graqlInsertQuery + = “insert $ call(caller:$ caller,callee:$ callee)isa call;” + “$ call已经开始” + 来电。at(“started_at”)。asString()+ “;” + “$ call has duration” + call。在(“持续时间”)。asInteger()+ “;” ; return graqlInsertQuery ; } }); 回报 输入 ; } }input.getDataPath() 会回来的 data/calls 。
鉴于 call 是
{ caller_id:“44 091 XXX” ,callee_id:“00 091 XXX” ,started_at:2018 - 08 - 10 T07:57:51,持续时间:148 }input.template(call) 将返回
比赛 $呼叫者 ISA 人 拥有 电话- 数字 “+44 091 XXX” ; $被叫 ISA 人 拥有 电话- 数字 “+00 091 XXX” ; insert $ call(caller:$ caller,callee:$ callee)isa call ; $电话 已经 开始- 在 2018 - 08 - 10 T07:57:51 ; $电话 具有 持续时间 148 ;连接和迁移
现在我们已经为每个数据文件定义了数据路径和模板,我们可以继续连接我们的 phone_calls 知识图并将数据加载到其中。
//其他进口 进口 ai。grakn。GraknTxType ; 进口 ai。grakn。Keyspace ; 进口 ai。grakn。客户。Grakn ; 进口 ai。grakn。util。SimpleURI ; 导入 java。io。UnsupportedEncodingException ; 公共 类 迁移 { 抽象 静态 类 输入 {...} public static void main(String [] args){ 集合< Input > inputs = initialiseInputs(); connectAndMigrate(输入); } static void connectAndMigrate(Collection < Input > inputs){ SimpleURI localGrakn = new SimpleURI(“localhost”,48555); Keyspace keyspace = Keyspace。of(“phone_calls”); Grakn grakn = new Grakn(localGrakn); Grakn。会话 会话 = grakn。session(keyspace); 输入。forEach(输入 - > { 系统。出。的println(“[由加载” + 输入。getDataPath()+ “]成Grakn ...”); 尝试 { loadDataIntoGrakn(输入,会话); } catch(UnsupportedEncodingException e){ e。printStackTrace(); } }); 会议。close(); } static Collection < Input > initialiseInputs(){...} static void loadDataIntoGrakn(输入 输入,Grakn。会话 会话)抛出 UnsupportedEncodingException {...} }connectAndMigrate(Collection<Input> inputs) 是启动数据迁移到 phone_calls 知识图中 的唯一方法 。
此方法发生以下情况:
grakn 创建 Grakn实例 ,连接到我们在本地运行的服务器 localhost:48555 。
session 创建 A ,连接到键空间 phone_calls 。
对于 集合中的 每个 input 对象 inputs ,我们称之为 loadDataIntoGrakn(input, session) 。 这将负责将 input 对象中 指定的数据加载 到我们的键空间中。
最后 session 关闭了。
将数据加载到phone_calls
现在我们已经 session 连接到 phone_calls 键空间,我们可以继续将数据实际加载到我们的知识图中。
//进口 公共 类 迁移 { 抽象 静态 类 输入 {...} public static void main(String [] args){ 集合< Input > inputs = initialiseInputs(); connectAndMigrate(输入); } static Collection < Input > initialiseInputs(){...} static void connectAndMigrate(Collection < Input > inputs){...} static void loadDataIntoGrakn(输入 输入,Grakn。会话 会话)抛出 UnsupportedEncodingException { ArrayList < Json > items = parseDataToJson(输入); 物品。forEach(item - > { Grakn。交易 tx = 会话。交易(GraknTxType。WRITE); String graqlInsertQuery = input。模板(项目); 系统。出。println(“执行Graql查询:” + graqlInsertQuery); tx。graql()。解析(graqlInsertQuery)。execute(); tx。commit(); tx。close(); }); 系统。出。的println(“\ nInserted” + 项目。大小()+ “由项目[” + 输入。getDataPath()+ “]。到Grakn \ n”个); } static ArrayList < Json > parseDataToJson(输入 输入)抛出 UnsupportedEncodingException {...} }为了将每个文件中的数据加载到Grakn中,我们需要:
检索一个 ArrayList JSON对象,每个对象代表一个数据项。 为此,我们呼吁 parseDataToJson(input) ,和
对于每个JSON对象 items :a)创建事务 tx ,b)构造 graqlInsertQuery 使用相应的 template ,c)运行 query ,d) commit 事务和e) close 事务。
有关创建和提交事务的注意事项: 为避免内存不足,建议在单个事务中创建和提交每个查询。 但是,为了更快地迁移大型数据集,每次查询都会发生一次,其中是保证在单个事务上运行的最大查询数。现在我们已经完成了上述所有操作,我们已准备好读取每个文件并将每个数据项解析为JSON对象。 这些JSON对象将被传递给 template 每个 Input 对象 上 的 方法 。
我们要编写实现 parseDataToJson(input) 。
DataFormat特定实现
parseDataToJson(input) 根据数据文件的格式 ,实现会 有所不同。
但无论数据格式是什么,我们都需要正确的设置来逐行读取文件。 为此,我们将使用 InputStreamReader 。
//其他进口 导入 java。io。InputStreamReader ; 导入 java。io。读者 ; 公共 类 迁移 { 抽象 静态 类 输入 {...} public static void main(String [] args){...} static void connectAndMigrate(Collection < Input > inputs){...} static Collection < Input > initialiseInputs(){...} static void loadDataIntoGrakn(输入 输入,Grakn。会话 会话)抛出 UnsupportedEncodingException {...} public static Reader getReader(String relativePath)throws UnsupportedEncodingException { 返回 新 的InputStreamReader(迁移。类。getClassLoader()。的getResourceAsStream(relativePath),“UTF-8”); } }解析CSV
我们将使用 Univocity CSV Parser 来解析我们的 .csv 文件。 让我们为它添加依赖项。 我们需要在 dependencies 标签中 添加以下内容 pom.xml 。
< 依赖> < groupId > com.univocity </ groupId > < artifactId > univocity-parsers </ artifactId > < version > 2.7.6 </ version > </ dependency >完成后,我们将编写 parseDataToJson(input) 解析 .csv 文件 的实现 。
//其他进口 进口 com。不公平。解析器。csv。CsvParser ; 进口 com。不公平。解析器。csv。CsvParserSettings ; 公共 类 迁移 { 抽象 静态 类 输入 {...} public static void main(String [] args){...} static void connectAndMigrate(Collection < Input > inputs){...} static Collection < Input > initialiseInputs(){...} static void loadDataIntoGrakn(输入 输入,Grakn。会话 会话)抛出 UnsupportedEncodingException {...} static ArrayList < Json > parseDataToJson(输入 输入)抛出 UnsupportedEncodingException { ArrayList < Json > items = new ArrayList <>(); CsvParserSettings settings = new CsvParserSettings(); 设置。setLineSeparatorDetectionEnabled(true); CsvParser 解析器 = 新的 CsvParser(设置); 解析器。beginParsing(getReader(输入。getDataPath()+ “的.csv” )); String [] columns = parser。parseNext(); String [] row ; 而((行 = 分析器。parseNext())!= 空){ Json item = Json。object(); 对于(诠释 我 = 0 ; 我 < 行。长度 ; 我++){ 项目。set(columns [ i ],row [ i ]); } 物品。add(item); } 返回 的项目 ; } public static Reader getReader(String relativePath)throws UnsupportedEncodingException { 返回 新 的InputStreamReader(迁移。类。getClassLoader()。的getResourceAsStream(relativePath),“UTF-8”); } }除了这个实现,我们还需要进行一次更改。
鉴于CSV文件的性质,生成的JSON对象将把 .csv 文件的 所有列 作为其键,即使该值不存在,它也将被视为一个 null 。
出于这个原因,我们需要在 person template 的 input 实例 方法中 更改一行 。
if (! person.has("first_name")) {...}
变
if (person.at("first_name").isNull()) {...} 。
阅读JSON
我们将使用 Gson的JsonReader 来读取我们的 .json 文件。 让我们为它添加依赖项。 我们需要在 dependencies 标签中 添加以下内容 pom.xml 。
< 依赖> < groupId > com.google.code.gson </ groupId > < artifactId > gson </ artifactId > < version > 2.7 </ version > </ dependency >完成后,我们将编写 parseDataToJson(input) 用于读取 .json 文件 的实现 。
//其他进口 进口 com。谷歌。gson。流。JsonReader ; 公共 类 迁移 { 抽象 静态 类 输入 {...} public static void main(String [] args){...} static void connectAndMigrate(Collection < Input > inputs){...} static Collection < Input > initialiseInputs(){...} static void loadDataIntoGrakn(输入 输入,Grakn。会话 会话)抛出 UnsupportedEncodingException {...} static ArrayList < Json > parseDataToJson(输入 输入)抛出 IOException { ArrayList < Json > items = new ArrayList <>(); JsonReader jsonReader = 新 JsonReader(getReader(输入。getDataPath()+ “上传.json” )); jsonReader。beginArray(); 而(jsonReader。hasNext()){ jsonReader。beginObject(); Json item = Json。object(); 而(jsonReader。hasNext()){ String key = jsonReader。nextName(); 开关(jsonReader。PEEK()){ 案例 STRING: 项目。集(键,jsonReader。nextString()); 打破 ; 案件 编号: 项目。集(键,jsonReader。nextInt()); 打破 ; } } jsonReader。endObject(); 物品。add(item); } jsonReader。endArray(); 返回 的项目 ; } public static Reader getReader(String relativePath)throws UnsupportedEncodingException { 返回 新 的InputStreamReader(迁移。类。getClassLoader()。的getResourceAsStream(relativePath),“UTF-8”); } }解析XML
我们将使用Java的内置 StAX 来解析我们的 .xml 文件。
要解析XML数据,我们需要知道目标标记的名称。 这需要在 Input 类中 声明 并在构造每个 input 对象 时指定 。
//进口 公共 类 XmlMigration { abstract static class Input { 字符串 路径 ; 串 选择 ; public Input(String path,String selector){ 这个。path = path ; 这个。selector = selector ; } String getDataPath(){ return path ;} String getSelector(){ return selector ;} abstract String template(Json 数据); } public static void main(String [] args){...} static void connectAndMigrate(Collection < Input > inputs){...} static Collection < Input > initialiseInputs(){ 集合< Input > inputs = new ArrayList <>(); 输入。add(new Input(“data / companies”,“company”){...}); 输入。添加(新 输入(“数据/人”,“人”){...}); 输入。add(new Input(“data / contracts”,“contract”){...}); 输入。add(new Input(“data / calls”,“call”){...}); 回报 输入 ; } static void loadDataIntoGrakn(输入 输入,Grakn。会话 会话)抛出 UnsupportedEncodingException,XMLStreamException {...} public static Reader getReader(String relativePath)throws UnsupportedEncodingException {...} }现在用于 parseDataToJson(input) 解析 .xml 文件 的实现 。
//其他进口 导入 javax。xml。流。XMLInputFactory ; 导入 javax。xml。流。XMLStreamConstants ; 导入 javax。xml。流。XMLStreamException ; 导入 javax。xml。流。XMLStreamReader ; 公共 类 XmlMigration { abstract static class Input { 字符串 路径 ; 串 选择 ; public Input(String path,String selector){ 这个。path = path ; 这个。selector = selector ; } String getDataPath(){ return path ;} String getSelector(){ return selector ;} abstract String template(Json 数据); } public static void main(String [] args){...} static void connectAndMigrate(Collection < Input > inputs){...} static Collection < Input > initialiseInputs(){ 集合< Input > inputs = new ArrayList <>(); 输入。add(new Input(“data / companies”,“company”){...}); 输入。添加(新 输入(“数据/人”,“人”){...}); 输入。add(new Input(“data / contracts”,“contract”){...}); 输入。add(new Input(“data / calls”,“call”){...}); 回报 输入 ; } static void loadDataIntoGrakn(输入 输入,Grakn。会话 会话)抛出 UnsupportedEncodingException,XMLStreamException {...} static ArrayList < Json > parseDataToJson(输入 输入)抛出 UnsupportedEncodingException,XMLStreamException { ArrayList < Json > items = new ArrayList <>(); XMLStreamReader r = XMLInputFactory。newInstance()。createXMLStreamReader(getReader(输入。getDataPath()+ “的.xml” )); 字符串 键 ; String value = null ; Boolean inSelector = false ; Json item = null ; 而([R 。hasNext()){ int event = r。next(); 开关(事件){ case XMLStreamConstants。START_ELEMENT: 如果(ř。号·getLocalName()。等于(输入。getSelector())){ inSelector = true ; item = Json。object(); } 打破 ; case XMLStreamConstants。字符: value = r。getText(); 打破 ; case XMLStreamConstants。END_ELEMENT: key = r。getLocalName(); 如果(inSelector && ! 关键。平等(输入。getSelector())){ 项目。set(key,value); } 如果(键。等于(输入。getSelector())){ inSelector = false ; 物品。add(item); } 打破 ; } } 返回 的项目 ; } public static Reader getReader(String relativePath)throws UnsupportedEncodingException {...} }把它放在一起
以下是我们 Migrate.java 将CSV数据加载到Grakn中的样子,并在这里找到 JSON 和 XML 文件的 样子 。
包 ai。grakn。例子 ; 进口 ai。grakn。GraknTxType ; 进口 ai。grakn。Keyspace ; 进口 ai。grakn。客户。Grakn ; 进口 ai。grakn。util。SimpleURI ; / ** *用于CSV,TSV和固定宽度文件的快速可靠的基于Java的解析器的集合 * @see <a href="https://www.univocity.com/pages/univocity_parsers_documentation"> univocity </a> * / 进口 com。不公平。解析器。csv。CsvParser ; 进口 com。不公平。解析器。csv。CsvParserSettings ; / ** *适用于Java的精简JSON库, * @see <a href="https://bolerio.github.io/mjson/"> mjson </a> * / 导入 mjson。杰森 ; 导入 java。io。InputStreamReader ; 导入 java。io。读者 ; 导入 java。io。UnsupportedEncodingException ; 导入 java。util。ArrayList ; 导入 java。util。收藏 ; 公共 课 CsvMigration { / ** *表示将输入文件链接到自己的模板函数的Input对象, *用于将Json对象映射到Graql查询字符串 * / abstract static class Input { 字符串 路径 ; public Input(String path){ 这个。path = path ; } String getDataPath(){ return path ;} abstract String template(Json 数据); } / ** * 1.创建Grakn实例 * 2.创建到目标键空间的会话 * 3.初始化输入列表,每个输入包含解析数据所需的详细信息 * 4.将csv数据加载到每个文件的Grakn * 5.结束会议 * / public static void main(String [] args){ 集合< Input > inputs = initialiseInputs(); connectAndMigrate(输入); } static void connectAndMigrate(Collection < Input > inputs){ SimpleURI localGrakn = new SimpleURI(“localhost”,48555); Grakn grakn = new Grakn(localGrakn); Keyspace keyspace = Keyspace。of(“phone_calls”); Grakn。会话 会话 = grakn。session(keyspace); 输入。forEach(输入 - > { 系统。出。的println(“[由加载” + 输入。getDataPath()+ “]成Grakn ...”); 尝试 { loadDataIntoGrakn(输入,会话); } catch(UnsupportedEncodingException e){ e。printStackTrace(); } }); 会议。close(); } static Collection < Input > initialiseInputs(){ 集合< Input > inputs = new ArrayList <>(); //定义用于构建公司Graql插入查询的模板 输入。add(new Input(“data / companies”){ @覆盖 public String template(Json company){ 返回 “插入$ company isa company has name” + 公司。at(“name”)+ “;” ; } }); //定义用于构造人Graql插入查询的模板 输入。add(new Input(“data / people”){ @覆盖 public String template(Json person){ //插入人 String graqlInsertQuery = “insert $ person isa person has phone-number” + person。at(“phone_number”); 如果(个人。在(“FIRST_NAME” )。参考isNull()){ //人不是客户 graqlInsertQuery + = “has is-customer false” ; } else { //人是顾客 graqlInsertQuery + = “has is-customer true” ; graqlInsertQuery + = “有名字” + 人。at(“first_name”); graqlInsertQuery + = “有姓氏” + 人。at(“last_name”); graqlInsertQuery + = “有城市” + 人。在(“城市”); graqlInsertQuery + = “有年龄” + 人。在(“年龄”)。asInteger(); } graqlInsertQuery + = “;” ; return graqlInsertQuery ; } }); //定义用于构造合同的模板Graql插入查询 输入。add(new Input(“data / contracts”){ @覆盖 public String template(Json contract){ //匹配公司 String graqlInsertQuery = “匹配$ company isa company has name” + contract。at(“company_name”)+ “;” ; //匹配人 graqlInsertQuery + = “$ customer isa person has phone-number” + contract。at(“person_id”)+ “;” ; //插入合同 graqlInsertQuery + = “insert(provider:$ company,customer:$ customer)isa contract;” ; return graqlInsertQuery ; } }); //定义用于构造调用Graql插入查询的模板 输入。add(new Input(“data / calls”){ @覆盖 public String template(Json call){ //匹配来电者 String graqlInsertQuery = “match $ caller isa person has phone-number” + call。at(“caller_id”)+ “;” ; //匹配被叫者 graqlInsertQuery + = “$ callee isa person has phone-number” + call。at(“callee_id”)+ “;” ; //插入电话 graqlInsertQuery + = “insert $ call(caller:$ caller,callee:$ callee)isa call;” + “$ call已经开始” + 来电。at(“started_at”)。asString()+ “;” + “$ call has duration” + call。在(“持续时间”)。asInteger()+ “;” ; return graqlInsertQuery ; } }); 回报 输入 ; } / ** *将csv数据加载到我们的Grakn phone_calls键空间: * 1.将数据项作为json对象列表获取 * 2.对于每个json对象 * 一个。创建Grakn事务 * b。构造相应的Graql插入查询 * C。运行查询 * d。提交交易 * e。关闭交易 * * @param输入包含解析数据所需的详细信息 * @param会话将创建一个事务 * @throws UnsupportedEncodingException * / static void loadDataIntoGrakn(输入 输入,Grakn。会话 会话)抛出 UnsupportedEncodingException { ArrayList < Json > items = parseDataToJson(输入); // 1 物品。forEach(item - > { Grakn。交易 tx = 会话。交易(GraknTxType。WRITE); // 2a String graqlInsertQuery = input。模板(项目); // 2b 系统。出。println(“执行Graql查询:” + graqlInsertQuery); tx。graql()。解析(graqlInsertQuery)。execute(); // 2c tx。commit(); // 2d tx。close(); // 2e }); 系统。出。的println(“\ nInserted” + 项目。大小()+ “由项目[” + 输入。getDataPath()+ “]。到Grakn \ n”个); } / ** * 1.通过流读取csv文件 * 2.将每行解析为json对象 * 3.将json对象添加到项列表中 * * @param输入用于获取数据文件的路径,减去格式 * @return json对象列表 * @throws UnsupportedEncodingException * / static ArrayList < Json > parseDataToJson(输入 输入)抛出 UnsupportedEncodingException { ArrayList < Json > items = new ArrayList <>(); CsvParserSettings settings = new CsvParserSettings(); 设置。setLineSeparatorDetectionEnabled(true); CsvParser 解析器 = 新的 CsvParser(设置); 解析器。beginParsing(getReader(输入。getDataPath()+ “的.csv” )); // 1 String [] columns = parser。parseNext(); String [] row ; 而((行 = 分析器。parseNext())!= 空){ Json item = Json。object(); 对于(诠释 我 = 0 ; 我 < 行。长度 ; 我++){ 项目。set(columns [ i ],row [ i ]); // 2 } 物品。add(item); // 3 } 返回 的项目 ; } public static Reader getReader(String relativePath)throws UnsupportedEncodingException { 返回 新 的InputStreamReader(CsvMigration。类。getClassLoader()。的getResourceAsStream(relativePath),“UTF-8”); } }加载时间
运行 main 方法,坐下来,放松并观察日志,同时数据开始涌入Grakn。
回顾一下
我们从设置项目和定位数据文件开始。
接下来,我们继续设置迁移机制,该机制独立于数据格式。
然后,我们了解了如何将具有不同数据格式的文件解析为JSON对象。
最后,我们运行了 使用给定 main 方法触发 connectAndMigrate 方法的方法 inputs 。 这将数据加载到我们的Grakn知识图中。
扫一扫,关注我们
